Deze blog is een onderdeel van de reeks: ‘Data structuur: de basis’
Verzamelen van de juiste data: Schone Data
Om waardevolle inzichten uit je data te kunnen verkrijgen is het belangrijk dat je begint met ‘schone data’. Vaak is een datawetenschapper redelijk veel tijd kwijt met het opschonen van data, voordat er analyses kunnen worden gemaakt om inzichten te verkrijgen. Door iets verder in te gaan op het proces dat een data wetenschapper doorloopt om de data op te schonen, krijg je hopelijk een beter beeld van wat ‘schone data’ is.
Data opschonen
Data opschonen verwijst naar het proces waarbij het onjuiste, onvolledige, onnauwkeurige, irrelevante of ontbrekende deel van de data wordt geïdentificeerd en vervolgens naar behoefte wordt aangepast, vervangen of verwijderd. Data is essentieel voor analyse en machine learning, maar als het gaat om data uit de echte wereld, is de kans groot dat gegevens onvolledige, inconsistente of ontbrekende waarden bevatten. Daarom kan het belang van het opschonen van data niet genoeg worden benadrukt. Ongeacht het algoritme dat je gebruikt geldt dat wanneer je data slecht is, je ook slechte of onbruikbare resultaten uit je analyse krijgt. Professionele datawetenschappers weten dit maar al te goed, het opschonen van data neemt tot 80% (!) van de tijd in beslag die aan een data science-project wordt besteed.
Missende waardes
Missende waardes zijn misschien wel het meest voorkomend als we het hebben over niet schone data. Deze waarden hebben meestal de vorm van NaN of None in een tabel. Dit is bijvoorbeeld het geval wanneer je je gegevens in Excel opent en er lege cellen zijn. Ontbrekende waarden kunnen ook leiden tot modellen die NaN-waarden voorspellen, wat we natuurlijk niet willen. Om met ontbrekende data om te gaan, is het belangrijk om de oorzaak ervan te achterhalen. Dit zal je helpen bij het beslissen over de beste manier om ermee om te gaan.
Er zijn verschillende oorzaken van missende waarden. Sommige waarden ontbreken omdat ze niet bestaan, andere ontbreken vanwege een onjuiste verzameling of een slechte data invoer. Als iemand bijvoorbeeld vrijgezel is en een vraag is enkel van toepassing op gehuwden, bevat de vraag een ontbrekende waarde. In dergelijke gevallen zou het verkeerd zijn om een waarde voor die vraag in te vullen. Hoe ga je om met deze ontbrekende waarden? Dit hangt af van het type data dat je verzamelt:
Data Types
- Numerieke data: je kunt voor ontbrekende waardes een 0 of het gemiddelde invullen;
- Tekstuele data: tekst is meestal niet relevant voor (basis) analyse, bijv. wanneer een kolom de productbeschrijving van een item bevat;
- Categorische data: als er een rij is die niet in de beschikbare categorieën valt, kun je een nieuwe categorie “Geen categorie” of “Overig” aanmaken. Die kan worden gebruikt om de lege waarden op te vullen;
- Datums: als een datum ontbreekt, terwijl dit essentieel is voor je analyse, kun je het beste de hele rij verwijderen als je de datum niet meer kunt herinneren/achterhalen. Het verwijderen van rijen of kolommen heeft de minste voorkeur (verlies van data!), maar is een goed alternatief als je de ontbrekende waarden niet kunt invullen.
Inconsistente data
Dit gebeurt meestal bij tekstuele of categorische data. Als je bijvoorbeeld de namen van verschillende landen moet opschrijven, kan werknemer nr. 1 “nederland” schrijven, werknemer nr. 2 schrijft “Nederland” werknemer nr. 3 schrijft “Holland”. Hoewel ze allemaal hetzelfde bedoelen, is het anders geschreven en zal een computer ze niet als gelijk beschouwen. Als we een analyse zouden doen op basis van de demografische gegevens van de klant, zou het resultaat van de computer zijn dat er één persoon in “nederland”, “Nederland” en “Holland” woont in plaats van 3 personen in Nederland.
Dus hoe ga je om met deze inconsistente data? Zoek zelf uit hoe je de data nu verzamelt. Is het mogelijk dat je medewerkers bepaalde waarden invullen? Zo ja, worden ze beperkt door een keuzemenu (consistente data) of is het een open tekstveld dat alle verschillende soorten waardes toestaat (inconsistente data). Als het laatste het geval is, controleer dan je gegevens op inconsistenties en probeer open velden te voorkomen; kies liever voor keuzemenu’s of schrijf duidelijke instructies voor het invoeren van de gegevens.
Voorbeeld
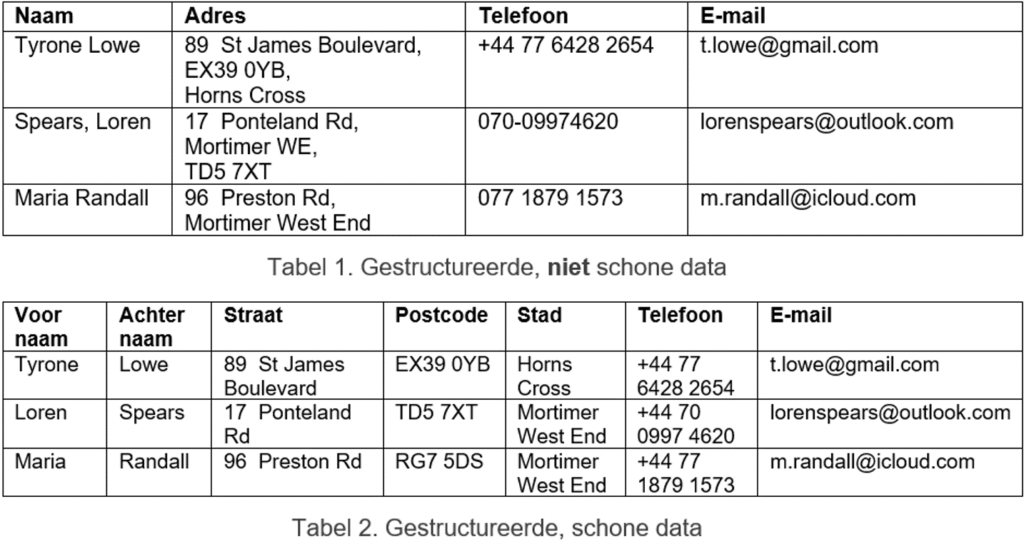
Kun je de verschillen zien tussen de schone en niet schone data? Om je te helpen:
- ‘Voornaam’ en ‘achternaam’ zijn gescheiden in kolommen om duidelijk te specificeren wat bedoeld wordt en in welke volgorde. Zo wordt een nieuwsbrief altijd verstuurd aan de juiste voornaam.
- ‘Adres’ is opgesplitst in ‘straat’, ‘postcode’ en ‘stad’ om problemen met bijvoorbeeld een bestelling te voorkomen
- ‘Stad’ is consequent opgeslagen (Mortimer WE / Mortimer West End)
- ‘Telefoon’ is consequent opgeslagen met de landcode
Ter reflectie
Wij hopen je met deze blog een beter beeld te hebben geven van wat wij verstaan onder schone data. Ter reflectie kun je jezelf de volgende vragen stellen:
- Hoe schoon is de data in jouw systemen?
- In welke databronnen wordt data op een schone en consistente manier verzameld?
- Voor welke databronnen geldt dit (nog) niet?
- Welke stappen kun je zetten om de data kwaliteit van deze bronnen te verbeteren?
Wil jij aan de slag met de data die je al hebt verzameld?
Wij helpen je graag mee om je data op te schonen en hier de eerste interessante inzichten uit te halen. Stuur ons even een bericht en dan plannen we samen een gesprek in om te kijken waar je ambities liggen en hoe we die met de data die je al hebt verzameld waar kunnen maken.
Wil je nog iets dieper begrijpen hoe je je data infrastructuur op de juiste manier inricht? Lees dan de blog die wij hebben geschreven over het belang van Relationele Databases.